Uma abordagem moderna de observabilidade com OpenTelemetry, Logstash e Splunk
Ferramentas legadas de monitoramento costumam vir acompanhadas de um alto custo e baixa flexibilidade. Se você já se sentiu preso a um fornecedor específico (vendor lock-in) ou atolado em pipelines de dados complexos, você não está sozinho. Recentemente, encarei esse desafio de frente ao construir um projeto de prova de conceito (PoC) que aproveita frameworks open source como OpenTelemetry e Logstash para criar uma stack de observabilidade escalável, econômica e altamente sustentável.
Este guia compartilha minha jornada e oferece um blueprint prático de como você pode construir um sistema semelhante. Ao deslocar a transformação e o enriquecimento de dados do Splunk para o Logstash, conseguimos reduzir significativamente os custos de licenciamento, simplificar a arquitetura e desbloquear o verdadeiro potencial dos padrões abertos.
Por que isso importa
O objetivo central deste projeto foi deixar de depender do Splunk para todo o processamento de dados e utilizá-lo principalmente como uma camada poderosa de visualização. Essa mudança estratégica traz diversos benefícios importantes:
- Redução de custos: ao mover transformações complexas de dados para o Logstash, minimizamos a quantidade de dados brutos ingeridos pelo Splunk, o que impacta diretamente os custos de licenciamento.
- Escalabilidade: a arquitetura foi desenhada para escalar horizontalmente, permitindo adicionar mais hosts e métricas sem reprojetar o pipeline.
- Independência de fornecedor: ao adotar padrões abertos como OpenTelemetry e OpenMetrics, o pipeline não fica preso a um único vendor.
- Manutenibilidade: pipelines modulares e versionados tornam o Logstash mais simples de manter, depurar e atualizar.
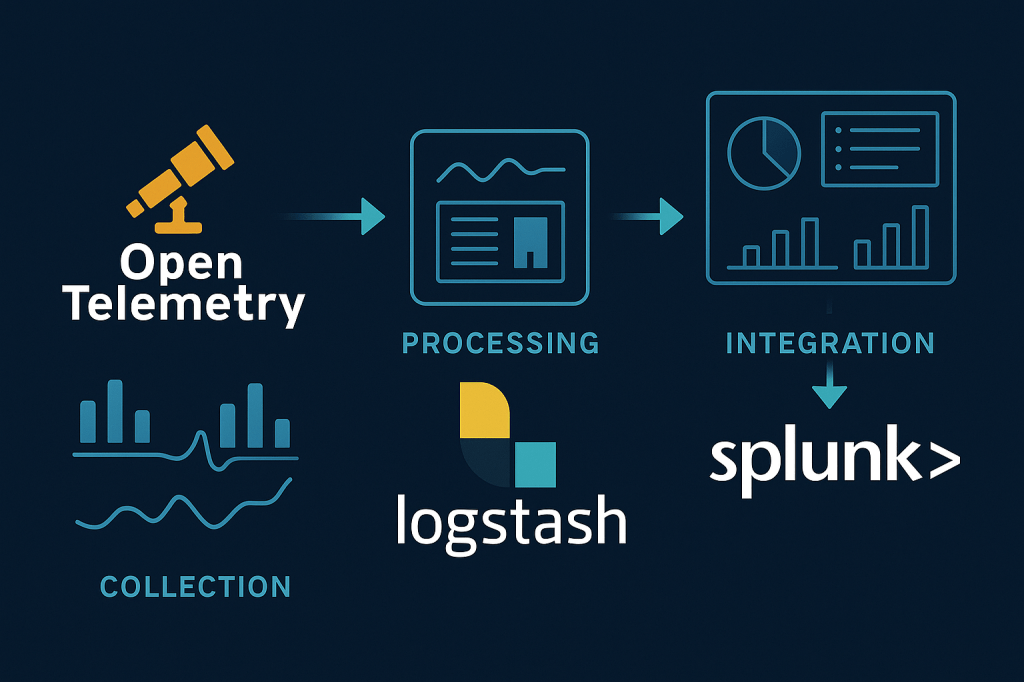
A arquitetura: um pipeline em três estágios
A arquitetura proposta se baseia em três etapas principais: coleta, processamento e integração.
1. Coleta
Um agente leve do OpenTelemetry é implantado em cada host, como servidores ou containers de aplicação. Ele coleta dados brutos de telemetria — métricas do sistema, logs de aplicação ou dados customizados — e encaminha tudo para um hub central.
2. Processamento
O hub central combina um OpenTelemetry Collector e uma instância do Logstash. O Collector realiza tarefas básicas como batching e exporta os dados para o Logstash com baixa latência. A partir daí, o Logstash executa todo o enriquecimento e transformação necessários.
3. Integração
Após serem transformados em um formato padronizado, os dados são enviados pelo Logstash ao Splunk via HTTP Event Collector (HEC), ficando prontos para visualização em dashboards.
Plugins personalizados do Logstash: escalabilidade e organização
Um dos pilares deste projeto é o uso de plugins personalizados para transformar dados no Logstash. Essa abordagem mantém o pipeline principal limpo e concentra a lógica individualizada em componentes separados.
Os plugins seguem a convenção appview_<nome>. Por exemplo:
appview_hostpara métricas de CPU e memóriaappview_dbpara métricas de banco de dados
O PoC já inclui diversos plugins prontos para demonstrar o conceito.
Como criar e implantar um novo plugin
Adicionar um novo plugin segue um fluxo simples:
- Gerar a estrutura com o gerador oficial de plugins do Logstash.
- Escrever a lógica de transformação no arquivo Ruby.
- Construir o
.gemcom o plugin. - Instalar o
.gemno servidor de Logstash usandologstash-plugin install.
O projeto contém ainda um script (install-appview-plugin.sh) que automatiza o download e a instalação de plugins a partir de um repositório privado de Gems, ideal para pipelines CI/CD.
Enriquecimento de dados no Logstash
Dados sem contexto são pouco úteis. Por isso, o enriquecimento de dados ocorre diretamente no Logstash usando o plugin logstash-filter-csv. Ele permite realizar consultas contra arquivos CSV externos — como mapear o nome de um host para o tenant correspondente.
Esses arquivos CSV são carregados em um banco de dados H2 em memória para acelerar o processo. Essa decisão arquitetural reduz drasticamente a latência, mantém a eficiência mesmo com alto volume e centraliza o enriquecimento em uma fonte única e de alta performance.
Passo a passo prático
O projeto foi estruturado para rodar facilmente em um ambiente Docker, replicando uma arquitetura de produção.
- Certifique-se de que Docker ou Podman está instalado.
- Clone o repositório público do GitHub.
- Na raiz do projeto, execute:
podman-compose up --buildoudocker-compose up --build - Acesse o Splunk em
http://localhost:8000com credenciaisadmin:changemee execute a busca:index=observability_index | sort -_time | table alert_value, blacklist_alerts, instance, metric_label, metric_unit, metric_value, source_host, threshold1, threshold2, threshold3, threshold4, tower, add_info, _time
Conclusão
O projeto mostra como construir uma plataforma de observabilidade moderna, escalável e de baixo custo utilizando OpenTelemetry, Logstash e Splunk. A combinação de padrões abertos, plugins customizados e enriquecimento eficiente cria uma solução robusta e preparada para o futuro.
A documentação completa está disponível no GitHub, incluindo um README detalhado e o arquivo Project Documentation.md, que descreve os objetivos iniciais, entregáveis e decisões arquiteturais tomadas durante o PoC.oject Documentation.md com os objetivos iniciais, entregáveis e decisões arquiteturais.
Project Repository: https://github.com/diegodss/opentelemetry-logstash-splunk






Deixe um comentário